字典树的实现和应用
1.概述
1.1 基础概念
字典树,又称为单词查找树,Tire树,它是一种树形结构,它是一种hash树的变种.
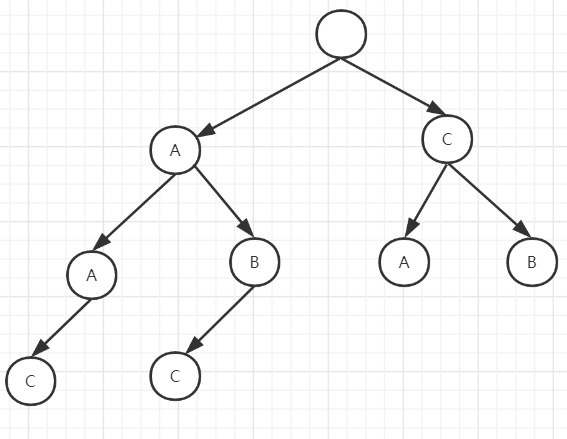
1.2 基本性质
- 根节点不包含字符,除根节点外的每一个节点包含一个字符
- 从根节点到某一个节点,路上结果的字符链接起来,就是该节点对应的字符串.
- 每个节点对应的字符串都不相同
1.3 应用场景
典型应用场景是用于统计,排序和保存大量的字符串(不仅限于字符串),经常被搜索引擎用系统用于文本词频统计.
2. 代码实现
2.1 定义字典树节点
字典树节点包含四个关键的属性,分别是
- 由根节点至该节点组成的字符串出现的次数
- 所有的子节点(子节点也是字典树节点)
- 是否是叶子节点
- 节点的值
1 | public class TrieNode { |
2.2 构建一颗字典树
字典树有关键属性
- 节点数
- 根节点
1 | public class TrieTree { |
2.3 插入节点
1 |
|
2.4 查询路径为当前字符串的节点
1 | /** |
2.5 计算包含前缀的单词数量
1 | /** |
2.6 查询是否包含该字符串
1 | /** |
2.7 查询是否完美包含该字符串
1 | /** |
2.8 前序遍历
1 | public void preTraverse(){ |
3. 应用
leetcode-820.单词的压缩编码
https://leetcode-cn.com/problems/short-encoding-of-words/
3.1 解题思路
例如,如果这个列表是 [“time”, “me”, “bell”],我们就可以将其表示为 S = “time#bell#” 和 indexes = [0, 2, 5]。
我们可以先构建一个如下字典树.
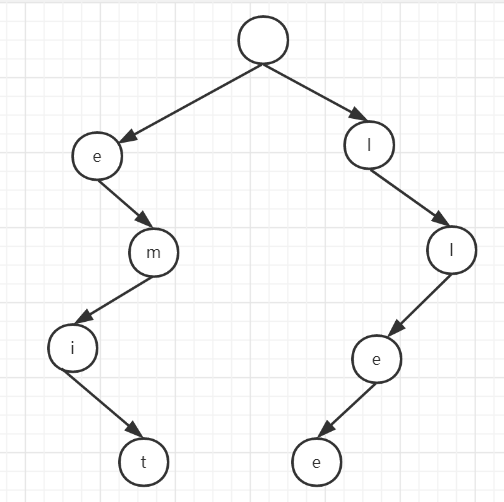
通过字典树,就可以求出本题的解.
3.2 解题代码
1 | class Solution { |